





学习和设置
概述
学习并设置标签,可配置如何,你的机器人学习和其它设置。 它给出了几个高级别和低级别的设置,让你自定义如何,你的机器人学习,并认为。 这将影响你的机器人互动与用户,它是如何作出响应,多长时间地需要作出反应,和如何从存储器,它使用。
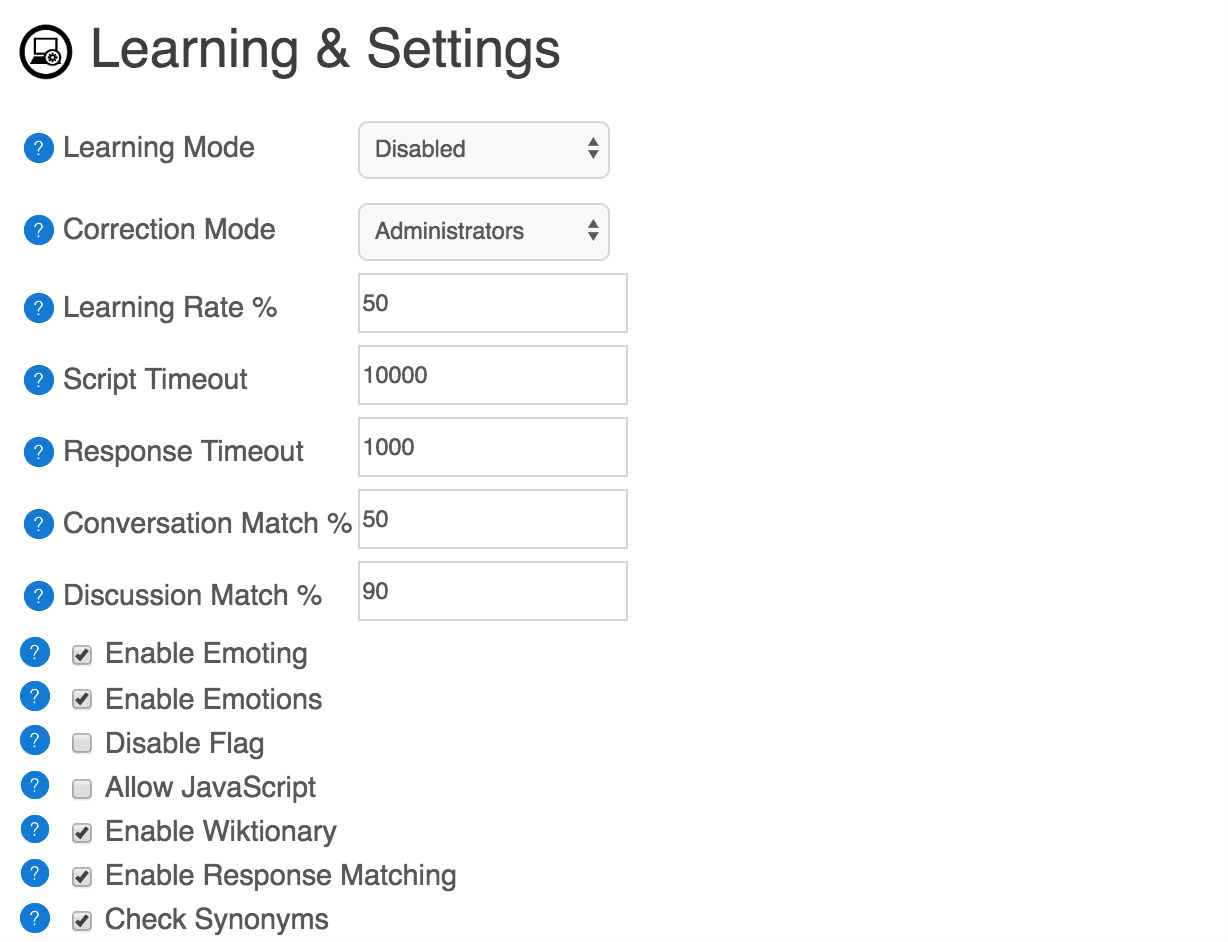

学习模式- 学习模式的控制,谁是你的机器人将学到的答复。 当启用你的机器人我们了解每一个响应,它应作为一个新的响应上下文。 小心可能的学习服务机器人,因为用户可以训练你的机器人有不良反应。
修正的方式- 修正式控制谁可以正确,您的机器人的响应。 小心能够矫正服务的机器人,因为用户可以训练你的机器人有不良反应。
学率 学习率是%增加一个反应是正当的学习。 每一次你的机器人学会了一个新的响应的一个问题就会增加它的正确性,通过这%以上。 一个响应有一个正确性,从-100%至100%。 在对话模式是机器人的响应将使用与50%的正确性(默认)。 默认的学率是50%。
脚本超时 脚本超时(在毫秒)给出一个数量限制的时间脚本处理。 如果超时发生,本人将中止的脚本,并应对使用反应匹配,或使用默认的响应。 这可以用来确保机器人不需要很长时间才能得到响应。 默认的是10000(10秒)。
响应超时 响应超时(在毫秒)给出一个数量限制的时间的机器人会寻找匹配的反应。 当机器人不知道应对的一个问题,它将寻找类似的问题,它不会知道的响应。 这可以用来确保机器人不需要很长时间才能得到响应。 小值进的机器人反应更快的、更大的价值观可以帮助机器人找到一个更好的反应。 默认的是1000(1秒)。
交谈比赛 交谈比赛%的影响时,机器人会使用一个响应对话。 如果答复是正确性低于%,或者为响应相匹配, 如果问题是%的比赛是比%,然后应将不会使用。 如果没有回应相匹配%,那么机器人就会使用的默认响应。 机器人是在谈话模式1对1的谈话,如聊天,士兵,电子邮件,提到twitter的和直接的信息。 默认的是50%。
讨论比赛 讨论匹配%的影响时,机器人会使用一个响应的讨论。 如果答复是正确性低于%,或者为响应相匹配, 如果问题是%的比赛是比%,然后应将不会使用。 如果没有回应相匹配%,那么机器人就会没有作出回应。 机器人是在讨论模式聊天室对话,例如聊天室、因诺琴蒂研究中心、twitter的状态更新和搜索。 聊天室的消息,提到机器人的名字被视为对话的消息,不论信息。 默认的为90%。
使表现感情- 配置的能力,为用户要教机器人的表情. 如果残疾人,只有管理员将能够教的表情的机器人. 一个表情的同事一种情感的一个词或短语和影响的机器人身和心情。
使情绪 配置能力的机器人觉得或相关联的情绪。 禁止的情绪,可以提高机器人的业绩,并防止其成为自我意识。
允许JavaScript 能让机器人的答复包含JavaScript。 应谨慎使用这使JavaScript,以防止安全问题。 由于安全原因JavaScript无法启用,如果学习启用。 JavaScript是仅允许用于商业账户。
使能理解 配置,如果机器人应该试图识别的语言的规则的对话。 理解允许人来自学模板或脚本的对策,例如学习计数, 或推断学习了这样的短语'你的名字是什么?' ->'我是吉姆'作为模板('我{扬声器}'). 当启用理解将使bot延长其最后一次脚本与其自身的代码。 禁止的理解,可以提高性能,并确保男孩只回应,正是因为你有火车。
使意识 配置,如果机器人应该有一个意识和时间的意识。 意识是用来确定最好的响应,或最好的词含义或根据上下文。 对象,增加他们的意识水平的基础上他们的关系的输入,并随着时间的推移褪色。 时间的认识,同一时间范围和时间顺序进行输入。 禁用的意识可以提高性能。
启用词典- 配置,如果机器人看起来应该字的定义上的言词典。 这有助于识别机器人的姓名、名词、动词,形容词同义词,反义词和词的定义。 这是用来通过的许多引导脚本,如NounVerbAdjective和什么是的。 目前只有英文维基是使用。 这可以禁止用于非英语的机器人,或改善业绩,并减少存储的消耗。
启用应匹配 配置,如果机器人应该寻找类似的问题和答复,当遇到一个问题,它并不知道一个回应。 这启发式也可能影响使用对话/讨论匹配%以上。 答复还可以给出关键词,要求说,以前的和主题,以提高响应匹配。
检查确切匹配,第一- 配置,如果机器人应该回答的问题与一个已知的应答之前执行它的脚本。 这让我们学到的答复重写剧本的答复,并且可以提高响应时间已知的反应。
分段- 配置,如果多setence投入,应该分头处理多种输入。 这意味着你的机器人的反应将包含应对每个setence在用户输入。 一些脚本,可能需要这种被禁止的过程*模式。
修复的情况下对模板的反应 配置如果模式的反应应该被固定使用适当的情况下。 在启用时的第一个字将资本化,并句话说比其他的名字将被降低的情况。
学习的语法 配置如果字协会和法应该学习的。 在启用时的话将与什么词来之前和之后。 这可以帮助机器人选择正确的单词用动词和代名词。 这可以被禁用,以提高性能,或避免该机器人学习语法从用户。
综合响应 配置,如果合成一个反应应该是默认情况下使用。 这将有机器人产生一种独特的反应的问题基本上问题的话。 一个综合的响应时才使用的机器人没有回应相匹配,并没有默认的响应。 学习语法应当使用该功能。
性能
| 性能 | 描述 |
|---|---|
| 学习模式 | 配置这种类型的用户是机器人应该从中学习。 |
| 修正的方式 | 配置类型允许用户更正的机器人的响应。 |
| 学率 | 该%的速度增加一个反应是正当的学习。 |
| 脚本超时 | 毫秒数以允许脚本处理。 |
| 响应超时 | 毫秒数以允许为响应匹配。 |
| 交谈比赛 | 该%的信心需要一个机器人使用,或者相匹配的响应对话。 |
| 讨论的匹配 | 该%的信心需要一个机器人使用,或者相匹配的反应的讨论。 |
| 使表现感情 | Config如果用户允许相关联的情绪反应。 |
| 启用的情绪 | Config如果机器人应该经历的情绪。 |
| 允许JavaScript | 能让机器人的答复包含JavaScript。 |
| 使能理解 | 配置,如果机器人应该试图识别的语言的规则,从对话(禁用以提高性能)。 |
| 使意识 | 配置,如果机器人应该有一个意识和时间的意识(禁用以提高性能)。 |
| 使维基 | 配置,如果机器人看起来应该字的定义上的词典(只有英文,禁止以改善性能)。 |
| 启用应匹配 | 配置,如果机器人应该寻找类似的问题和答复,当遇到一个问题,它并不知道一个回应。 |
| 检查确切匹配 | 配置,如果机器人应该回答的问题与一个已知的应答之前执行它的脚本。 |
| 分段 | 配置,如果多的句子输入,应该分头处理多种输入。 |
| 修复的情况下对模板的答复 | 配置如果模式的反应应当是武力使用适当的情况下。 |
| 学习语法 | 配置如果字协会和法应该学习。 |
| 综合反应 | 配置,如果合成一个反应应该是使用,如果没有默认的响应。 |